
📋 목차
크롤링 오류는 주로 URL의 유효성, 서버 설정, 콘텐츠 차단, 또는 동적 로딩 문제에서 발생합니다. 본 글에서는 크롤링 오류의 주요 원인과 이를 해결하는 실질적인 방법을 자세히 살펴봅니다.
1. URL 구조 및 유효성 확인
URL 구조 및 유효성 확인
올바른 URL 확인
- 정확한 URL 입력 여부 확인
- 크롤링하려는 URL에 오타나 누락된 부분이 없는지 확인합니다.
- 특수 문자 확인
- URL에 포함된 특수 문자(% 등)나 잘못된 인코딩이 크롤링 오류를 유발할 수 있으므로, 표준 인코딩을 사용합니다.
- HTTP와 HTTPS 일관성 유지
- HTTP와 HTTPS를 혼용하면 크롤러가 올바른 페이지를 찾지 못할 수 있으므로, 하나의 프로토콜로 통일하세요.
- 사이트맵 활용
- 최신 사이트맵을 생성하고, 사이트맵 파일을 Search Console이나 Bing Webmaster Tools에 제출합니다.
Broken Link 확인
- Broken Link Checker
- Broken Link Checker 같은 도구를 사용하여 잘못된 링크나 깨진 링크를 식별합니다.
- 무료 도구: Dead Link Checker.
- 404 오류 페이지 점검
- 404 오류 페이지로 연결되는 URL을 확인하고, 리디렉션을 설정하거나 페이지를 복구합니다.
2. robots.txt 설정 점검
robots.txt 설정 점검
robots.txt 파일 이해
robots.txt 파일은 크롤러가 웹사이트의 특정 페이지에 접근할 수 있는지 여부를 제어합니다. 설정이 잘못되면 크롤링이 차단될 수 있습니다.
설정 점검
- Disallow 규칙 확인
- 크롤링하려는 URL이 Disallow 규칙에 포함되어 있는지 확인합니다.

위와 같이 설정되면 /private/ 디렉토리는 크롤링되지 않습니다.
2. 사이트맵 위치 지정
robots.txt 파일에 사이트맵 위치를 명시하여 크롤러가 효율적으로 작동하도록 돕습니다.

3. Google의 robots.txt Tester 사용
- Google Search Console의 robots.txt Tester 도구를 사용하여 파일을 검증하고 문제가 있는 규칙을 수정합니다.
4. 크롤러별 접근 권한 설정
- 특정 크롤러에만 접근을 허용하거나 제한할 수 있습니다.

3. HTTP 상태 코드 오류 해결
HTTP 상태 코드 오류 해결
404 Not Found
- 원인: 요청한 URL이 존재하지 않거나 삭제된 경우 발생.
- 해결 방법:
- URL 확인: 올바른 URL인지 다시 확인.
- 리디렉션 설정: 삭제된 페이지를 관련 콘텐츠로 리디렉션(301 리디렉션).
- 사이트맵 업데이트: 삭제된 URL을 제거하거나 수정.
- 404 페이지 사용자 정의: 사용자 경험을 개선하기 위해 의미 있는 메시지를 포함.
403 Forbidden
- 원인: 서버 권한 문제로 인해 크롤러나 사용자 요청이 차단된 경우 발생.
- 해결 방법:
- 권한 확인: 웹 서버의 .htaccess 또는 권한 설정 파일을 점검.
- IP 차단 여부 확인: 크롤러의 IP가 차단되지 않았는지 확인.
- User-Agent 설정: 크롤러의 User-Agent를 웹 브라우저 User-Agent로 변경.
500 Internal Server Error
- 원인: 서버 부하, 코드 오류, 구성 문제 등으로 인해 발생.
- 해결 방법:
- 서버 로그 점검: 오류 로그를 확인해 문제의 원인을 파악.
- 서버 부하 감소: 요청 수를 줄이거나 크롤링 속도를 조절.
- 플러그인/모듈 확인: CMS 사용 시, 오류를 유발하는 플러그인을 비활성화.
429 Too Many Requests
- 원인: 서버가 과도한 요청을 감지하고 차단한 경우 발생.
- 해결 방법:
- 지연 시간 추가: 요청 간격을 늘려 서버 부하를 완화.
- API 문서 확인: 요청 제한(Throttle Rate)을 준수.
- 분산 요청: 프록시 서버를 사용하여 요청을 분산.
4. User-Agent 차단 문제 해결
User-Agent 차단 문제 해결
문제 진단
- 특정 User-Agent를 사용하는 크롤러가 차단될 경우 발생.
- 웹사이트가 크롤러를 의도적으로 제한하거나 비정상적 활동으로 간주.
해결 방법
- User-Agent 설정:
크롤링 도구에서 User-Agent를 실제 브라우저 User-Agent로 변

robots.txt 확인
웹사이트의 robots.txt 파일에서 크롤링 허용 여부 확인.
특정 User-Agent만 허용하거나 차단할 수 있음.
허가 요청
사이트 관리자에게 크롤링 허가를 요청하여 IP 및 User-Agent를 등록.
프록시 사용
- IP 차단이 함께 발생하면 분산 프록시를 활용해 요청을 우회.
5. 요청 속도 제한 및 우회
요청 속도 제한 및 우회 방법
요청 제한 문제
- 과도한 크롤링 요청으로 서버가 부하를 감지하거나 차단.
해결 방법
- 요청 간격 조정:
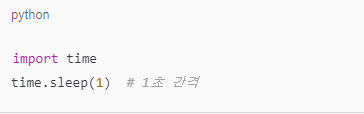
- 요청 사이에 지연 시간을 추가하여 서버 부하를 완화.
- robots.txt 및 API 문서 확인:
- 서버에서 허용하는 요청 속도 및 최대 요청 수 확인.
- API의 Rate Limit 정책 준수.
- Too Many Requests 오류 해결:
- Retry-After 헤더를 확인하여 서버가 요청을 재시도할 시간을 파악.
- 과도한 요청이 감지되면 일정 시간 대기.
- 분산 프록시 사용:
- 여러 IP 주소로 요청을 분산해 서버 부하를 최소화.
6. CAPTCHA 대응 방안
CAPTCHA 대응 방안
CAPTCHA는 자동화된 스크립트(봇)의 접근을 제한하기 위한 보안 장치로, 텍스트 인식, 이미지 선택, 클릭 인증 등을 요구합니다.
해결 방법
- CAPTCHA 우회 API 사용:
- CAPTCHA를 자동으로 해결해주는 서비스(API)를 활용.
- 대표적인 서비스:
- 예제 코드(Python):
import requests
api_key = "YOUR_API_KEY"
captcha_image = open("captcha_image.png", "rb")
response = requests.post(
"https://2captcha.com/in.php",
files={"file": captcha_image},
data={"key": api_key, "method": "post"}
)
print(response.text)
2. Headless 브라우저 사용:
- Selenium, Puppeteer 등의 도구를 사용하여 CAPTCHA를 처리.
- CAPTCHA를 수동으로 해결하고 세션을 저장해 지속적으로 사용.
from selenium import webdriver driver = webdriver.Chrome() driver.get("https://example.com") input("CAPTCHA를 해결한 후 Enter를 누르세요.")3. 관리자와 협력:
- 웹사이트 관리자에게 크롤링 목적과 의도를 설명하고 CAPTCHA 예외 처리를 요청.
- 정당한 이유로 허용받으면 효율성과 데이터 신뢰도가 향상.IP 주소 변경:
- CAPTCHA 발생 빈도를 줄이기 위해 VPN 또는 프록시 서버를 사용해 IP를 주기적으로 변경.
- 프록시 로테이션 도구 활용:
- Luminati
- Smartproxy
4. Rotating Proxies비용 절감 방법:
CAPTCHA가 자주 발생하는 경우, 사용자 세션 데이터를 저장해 반복 인증을 피함.
7. 동적 콘텐츠 크롤링 방법
동적 콘텐츠 크롤링 방법
JavaScript를 통해 동적으로 콘텐츠를 로드하는 웹사이트는 일반적인 크롤링 방식으로 데이터를 수집하기 어렵습니다.
해결 방법
- Headless 브라우저 활용:
- Selenium, Puppeteer, Playwright와 같은 도구를 사용하여 브라우저 환경에서 JavaScript를 처리.
Selenium 예제:
2. Ajax 요청 분석:
- 웹 브라우저의 개발자 도구(F12)를 열고 Network 탭에서 Ajax 요청을 모니터링.
- 데이터 API URL을 직접 호출해 JSON 또는 HTML 데이터를 수집.
import requests
response = requests.get("https://example.com/api/data")
print(response.json())
3, 정적 HTML 변환 옵션 확인:
- 일부 웹사이트는 SEO 또는 성능을 위해 정적 HTML 버전을 제공.
- ?nojs=true 또는 ?view=html 같은 URL 매개변수를 테스트.
4. API 활용:
- 웹사이트에서 공식적으로 제공하는 API가 있다면 이를 사용하는 것이 가장 안정적.
- API 키가 필요한 경우, 계정을 생성하고 인증 토큰을 요청.
5. Splash와 같은 렌더링 서비스 사용:
- Splash는 서버에서 JavaScript를 렌더링하고 HTML을 반환하는 도구.
Scrapy-Splash와 통합하여 사용:
6. HTML 스냅샷 사용:
- Google Cache 또는 Archive.org에서 HTML 스냅샷을 가져오는 방법도 고려.
❓ 크롤링 관련 자주 묻는 질문 FAQ
Q: 크롤링 중 403 오류가 발생하면 어떻게 해결하나요?
A: User-Agent를 변경하거나 서버 관리자에게 허가를 요청하세요.
Q: CAPTCHA를 어떻게 우회할 수 있나요?
A: CAPTCHA 우회 API나 Headless 브라우저를 사용해 처리하세요.
Q: 크롤링 속도를 조절하는 방법은?
A: 요청 간 지연 시간을 늘리거나 분산 프록시를 사용하세요.
Q: 404 오류를 해결하려면?
A: URL이 유효한지 확인하고 리디렉션을 설정하세요.
Q: 동적 콘텐츠를 크롤링하려면 어떻게 해야 하나요?
A: Headless 브라우저나 Ajax 요청을 분석해 데이터를 처리하세요.
Q: IP 차단을 피하려면?
A: 프록시 서버를 사용하여 IP 주소를 분산시키세요.
Q: robots.txt에서 허용된 URL만 크롤링하는 방법은?
A: robots.txt 파일을 확인하고 명시된 허용 경로를 따르세요.
Q: 크롤링 시도 시 웹사이트가 느려지면?
A: 요청 속도를 줄이고 서버 부하를 분산시키는 전략을 사용하세요.
'컴퓨터 관련 정보' 카테고리의 다른 글
| PDF Preview Handler 오류 해결 방법 (0) | 2024.12.11 |
|---|---|
| AppCrash 오류 해결 방법: 간단하고 효과적인 가이드 (0) | 2024.12.11 |
| 엑셀 시트 이름 충돌 오류 해결 방법! (2) | 2024.12.11 |
| Runtime Error 오류 해결 방법 총정리 (3) | 2024.12.10 |
| 마이크로 SD카드 인식 오류 해결 방법: 원인과 해결책 (0) | 2024.12.10 |